Incidents
Learn how to manage incidents and maintenance on your status page, including manual creation, automated incidents, and effective communication strategies.
Incident Management
Effective incident management is crucial for maintaining user trust during service disruptions. StatusPageOne provides comprehensive tools for both manual incident management and automated incident detection.
Understanding Incidents vs Maintenance
Incidents
Unexpected service disruptions that impact users:
- Service outages or failures
- Performance degradations
- Security issues affecting availability
- Database connectivity problems
- Third-party integration failures
Maintenance
Planned activities that may affect service availability:
- Scheduled system updates
- Database maintenance windows
- Infrastructure migrations
- Feature deployments
- Security patches
Incident Lifecycle
1. Detection and Creation
- Manual creation: Admin creates incident manually
- Automated detection: System automatically creates incidents based on monitor failures
- User reports: Information gathered from support tickets or user feedback
2. Investigation and Updates
- Initial response: Acknowledge the incident and begin investigation
- Regular updates: Provide status updates at regular intervals
- Progress communication: Share findings and resolution steps
3. Resolution and Follow-up
- Service restoration: Fix the underlying issue
- Verification: Confirm services are fully operational
- Post-incident review: Analyze cause and prevention measures
Manual Incident Creation
Creating an Incident
- Navigate to Incidents
- Go to Status Pages > Incidents
- Click Create Incident button
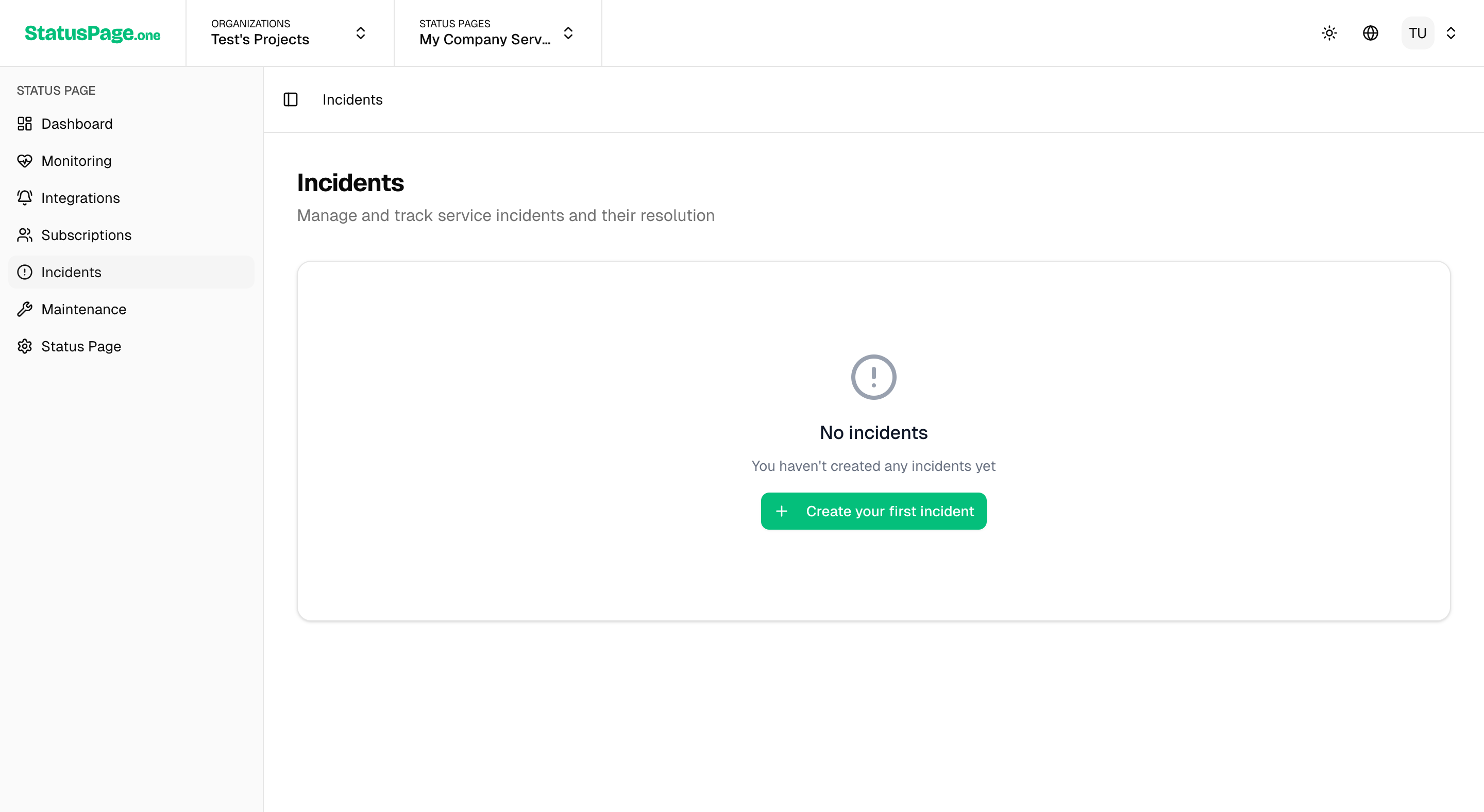
- Incident Details
- Title: Clear, descriptive title (e.g., "API Response Delays")
- Description: Detailed explanation of the issue and impact
- Severity: Choose from Minor, Major, or Critical
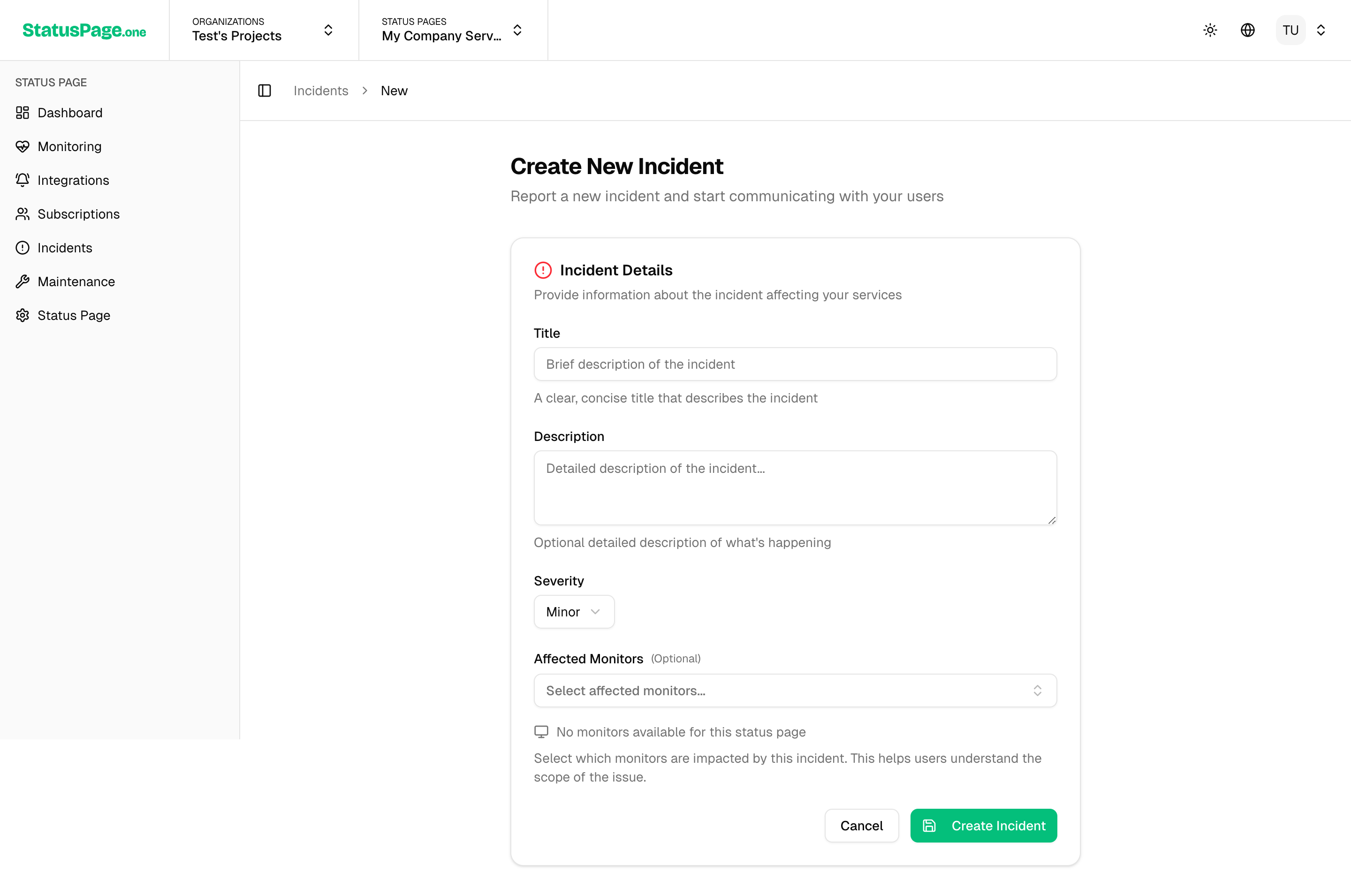
-
Affected Services
- Select which monitors/services are affected
- Multiple services can be associated with one incident
-
Initial Status
- Investigating: Currently diagnosing the issue
- Identified: Root cause has been found
- Monitoring: Fix applied, monitoring for stability
- Resolved: Issue completely resolved
Incident Severity Levels
Minor Incidents
- Limited impact on users
- Non-critical features affected
- Workarounds available
- Example: Secondary API endpoint slow response
Major Incidents
- Significant impact on core functionality
- Many users affected
- Limited workarounds
- Example: Database performance issues affecting all users
Critical Incidents
- Complete service unavailability
- All users affected
- No workarounds available
- Example: Complete system outage
Best Practices for Manual Incidents
Title Guidelines
- Be specific: "Payment Processing Delays" vs "System Issues"
- Avoid technical jargon: Use user-friendly language
- Keep it concise: 50 characters or less when possible
- Include impact: What users are experiencing
Description Writing
- Start with impact: What users are experiencing
- Provide context: When the issue started
- Avoid blame: Focus on resolution, not fault
- Set expectations: Estimated resolution timeframe if known
Automated Incident Generation
Configuration
Set up automatic incident creation for each monitor:
-
Navigate to Monitor Settings
- Go to Monitors > Select monitor > Settings
- Find Incident Configuration section
-
Enable Auto-Generation
- Toggle Auto-generate incidents to ON
- Configure failure thresholds and parameters
Auto-Generation Parameters
Failure Threshold
- Default: 3 consecutive failures
- Range: 1-10 consecutive failures
- Recommendation: 3-5 failures to avoid false positives
- Consideration: Balance between quick detection and false alarms
Failure Window
- Default: 5 minutes
- Range: 1-30 minutes
- Purpose: Time window to evaluate consecutive failures
- Example: 3 failures within 5 minutes triggers incident
Default Severity
- Minor: Non-critical services or internal tools
- Major: Important user-facing services (default)
- Critical: Essential services that block user workflows
Incident Grouping
Related monitor failures are automatically grouped:
Grouping Logic
- Time-based: Failures occurring within 10 minutes
- Status page: Only monitors from the same status page
- Related services: Services likely to fail together
Benefits
- Reduced noise: One incident instead of multiple
- Better communication: Consolidated updates
- Easier management: Single resolution workflow
Incident Updates and Communication
Status Update Types
Investigating
- When to use: Initial incident detection
- Message focus: Acknowledging the issue and beginning investigation
- Example: "We're investigating reports of slow API responses affecting user logins."
Identified
- When to use: Root cause has been determined
- Message focus: Explaining what caused the issue
- Example: "We've identified a database performance issue causing login delays. Our team is implementing a fix."
Monitoring
- When to use: Fix has been applied, monitoring for stability
- Message focus: Solution deployed, watching for full recovery
- Example: "The database issue has been resolved. We're monitoring the system to ensure full stability."
Resolved
- When to use: Issue is completely fixed and stable
- Message focus: Confirmation of resolution and any follow-up actions
- Example: "All systems are now fully operational. Login performance has returned to normal."
Update Best Practices
Frequency Guidelines
- Every 30 minutes for critical incidents
- Every hour for major incidents
- Every 2-4 hours for minor incidents
- More frequently during active resolution work
Communication Principles
- Be honest: Don't hide information or downplay issues
- Be clear: Use simple language everyone can understand
- Be timely: Don't wait for perfect information
- Be consistent: Match your tone across all updates
Update Template
**Status**: [Current status]
**Update**: [What's happening now]
**Impact**: [How users are affected]
**Next Steps**: [What we're doing next]
**ETA**: [Expected resolution time, if known]
Maintenance Management
Scheduling Maintenance
- Create Maintenance Event
- Go to Status Pages > Maintenance
- Click Schedule Maintenance
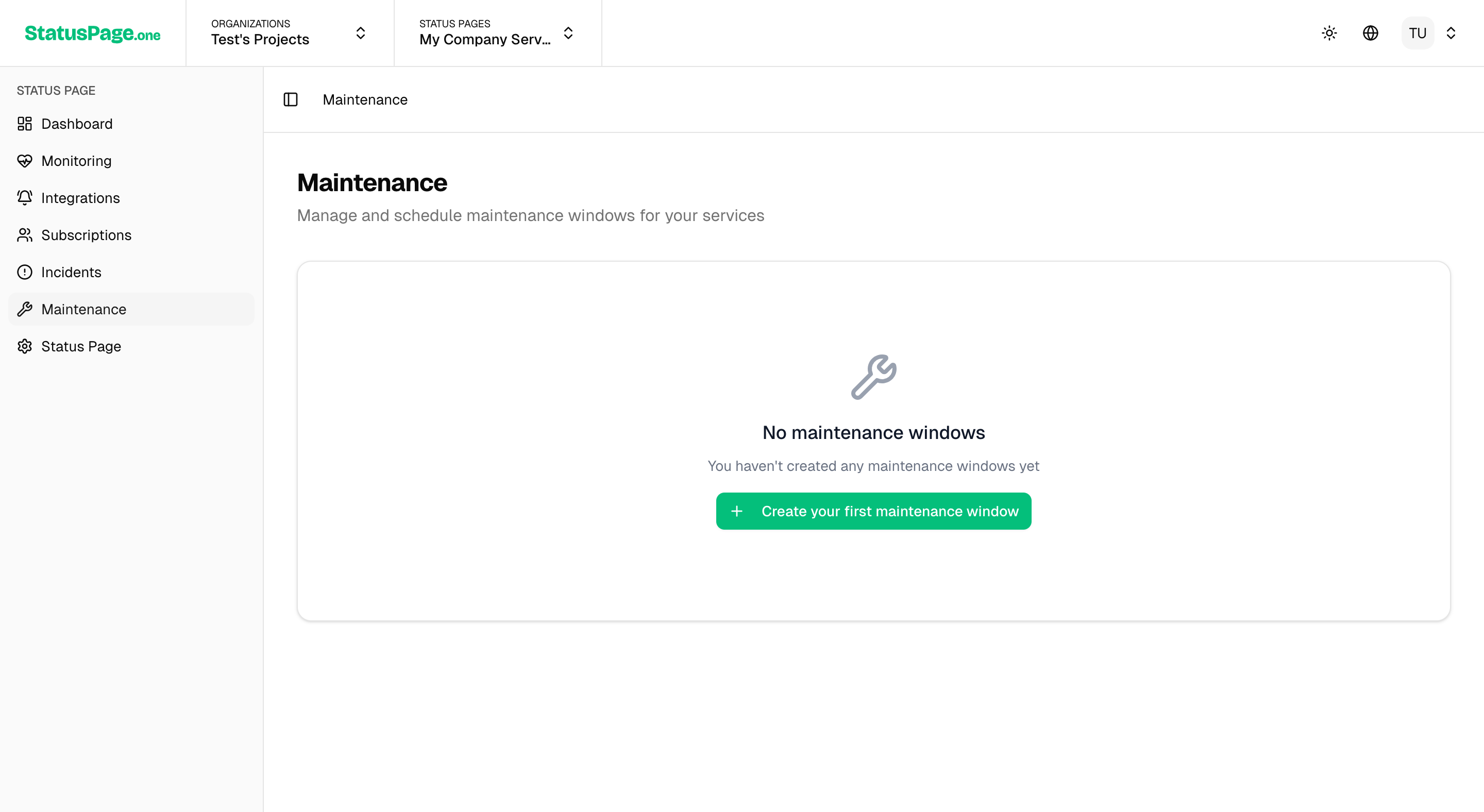
-
Maintenance Details
- Title: Clear description of the work
- Description: What's being updated and expected impact
- Affected Services: Which services may be impacted
-
Schedule Settings
- Start Time: When maintenance begins
- End Time: Expected completion time
- Time Zone: Displayed in user's local time zone
Maintenance Communication
Advance Notice
- 1 week minimum for major maintenance
- 72 hours minimum for minor maintenance
- 24 hours minimum for emergency maintenance
- Multiple reminders leading up to the event
During Maintenance
- Start notification: When maintenance begins
- Progress updates: If maintenance runs longer than expected
- Completion notification: When maintenance is finished
Maintenance Best Practices
Timing Considerations
- Off-peak hours: Schedule during lowest usage periods
- Time zones: Consider your global user base
- Avoid holidays: Don't schedule during major holidays
- Business impact: Consider business-critical times
Communication Strategy
- Multi-channel: Status page, email, in-app notifications
- Clear impact: Explain exactly what users will experience
- Backup plans: Have rollback procedures ready
- Contact information: Provide escalation contacts if needed
Subscriber Notifications
Automatic Notifications
When incidents or maintenance are created/updated:
- Email subscribers receive immediate notifications
- Slack integrations post to configured channels
- Notifications respect user subscription preferences
Notification Content
Email Notifications
- Subject line: Includes status page name and incident title
- Body content: Status update with timestamp and next steps
- Unsubscribe link: Easy opt-out for users
- Branding: Includes your logo and styling
Slack Notifications
- Rich formatting: Uses Slack's message formatting
- Status colors: Color-coded based on severity
- Action buttons: Links to full status page
- Thread organization: Updates post in threads for context
Post-Incident Procedures
Incident Resolution
Resolution Checklist
- Verify fix: Confirm the underlying issue is resolved
- Monitor stability: Watch for recurring problems
- Update status: Change incident status to "Resolved"
- Final communication: Notify users of complete resolution
- Document lessons: Record what was learned
Post-Mortem Process
When to Conduct
- All major incidents: Complete analysis required
- Critical incidents: Detailed post-mortem with timeline
- Recurring issues: Pattern analysis and prevention
- Customer impact: Significant user-facing problems
Post-Mortem Elements
- Timeline: Detailed sequence of events
- Root cause: Technical explanation of the failure
- Impact assessment: User and business impact
- Resolution steps: What was done to fix the issue
- Prevention measures: Steps to prevent recurrence
Integration with Monitoring
Monitor-to-Incident Flow
Monitor Failure → Threshold Check → Auto-Incident Creation → Notification Sending → Status Page Update
Configuration Tips
Threshold Tuning
- Start conservative: Use higher thresholds initially
- Monitor false positives: Adjust based on experience
- Service criticality: More sensitive for critical services
- Historical data: Use past incidents to calibrate
Incident Routing
- Service grouping: Related services share incident configurations
- Escalation paths: Define who gets notified for different severities
- Time-based rules: Different thresholds for business vs off hours
Metrics and Analysis
Incident Tracking
StatusPageOne automatically tracks:
- Incident frequency: How often incidents occur
- Resolution times: MTTR (Mean Time To Resolution)
- Severity distribution: Breakdown of incident types
- User impact: Affected user estimates
Performance Metrics
Key Indicators
- Uptime percentage: Overall service availability
- Incident count: Total incidents per time period
- Average resolution time: Speed of incident resolution
- User satisfaction: Subscriber feedback and engagement
Reporting
- Weekly summaries: Incident and maintenance reports
- Monthly trends: Long-term availability analysis
- Annual reviews: Year-over-year reliability improvements
- Custom exports: Data for internal analysis
Effective incident management builds user trust through transparent, timely communication during service disruptions while providing the tools needed for quick resolution and continuous improvement.
Improve this page
Found an error or want to contribute? Edit this page on GitHub.